Serveur IA de l’Université

Au cours de ma dernière année à l’université, nous avons reçu plusieurs serveurs, mais l’un d’entre eux était particulier : il contenait une NVIDIA RTX 6000 ADA, un nom qui ferait sursauter n’importe quel joueur s’il connaissait sa puissance (et son prix).
Il s’agissait d’une carte spéciale conçue pour les calculs complexes et l’intelligence artificielle : grâce à ses 40 Go de VRAM, elle pouvait gérer des modèles volumineux, allant d’un simple modèle linguistique à la génération de vidéos.
J’ai installé Debian dessus et j’ai passé toute la journée à me battre avec les pilotes NVIDIA, mais après un certain temps, j’ai réussi à lancer quelques modèles de test grâce à PyTorch ! Nous pouvions voir les possibilités infinies de cette machine.
Expériences#
Avant de totalement mettre en place le serveur avec une installation permanente, nous voulions expérimenter ce qu’il était possible de faire avec cette carte graphique.
Nous réfléchissions à la manière dont nous pourrions l’intégrer à nos serveurs génériques, en particulier notre n8n dont nous ne nous servions qu’assez peu (en particulier dû au fait que la fonctionnalité LDAP n’était pas disponible sur la version gratuite).
Nous avions trouvé un workflow assez intéressant où les documents de nos cours que nous déposions sur notre Nextcloud pouvaient être utilisés n8n pour être analysés et enregistrés par son RAG dans son “vector store” (sa base de connaissances).
À l’aide d’une installation de Ollama sur notre serveur d’IA, il était possible de l’ajouter à notre workflow. Avec quelques configurations dans n8n, il était maintenant possible de lui poser une question, et il répondait alors avec des informations sur les cours ! C’est à croire qu’il apprenait avec nous, et voir les nouvelles informations être ajouté était assez satisfaisant.
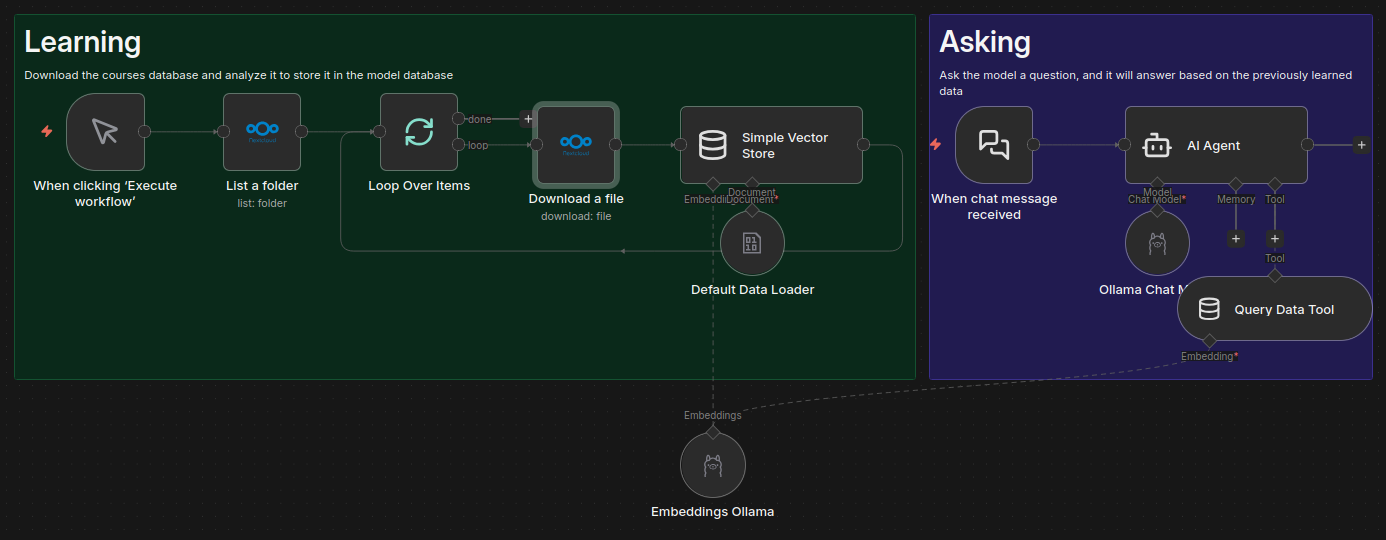
Dû au manque de compatibilité entre Nextcloud et n8n ainsi qu’à notre soif de conquête du serveur d’IA sur des modèles de traitement d’images ou de vidéos, nous n’avons pas utilisé très longtemps cet outil. En revanche, c’est celui que je recommanderai toujours aux futures promotions : des services, de l’automatisation, de l’IA, des APIs, toutes les étapes de ce projet concernent un domaine différent et se trouvent être extrêmement pédagogiques avec un résultat directement utile.
Serveur d’Inférence#
Le serveur est mis à disposition de tous les membres de la classe, et il faut donc que tout le monde puisse l’utiliser. Or, il n’est pas forcément facile de partager les capacités de calcul d’une carte graphique entre plusieurs personnes : Si nous sommes une dizaine, il faut se réserver ~5GB chacun ? Ce n’est pas plus utile que nos cartes graphiques personnelles.
Nous avions besoin d’une solution nous permettant à tous de pouvoir utiliser les pleines capacités du serveur sans pour autant se marcher sur les pieds.
Il fallait que n’importe puisse d’envoyer n’importe quel type de requête au serveur, le faisant automatiquement charger et décharger des modèles en fonction des requêtes afin que nous puissions rendre n’importe quel modèle disponible quand nous le voulions.
Malheureusement, il n’existait pas de solution directe : NVIDIA propose son “Triton Inference Server”, mais celui-ci est très difficile à configurer et garde toujours tous les modèles chargés, vLLM et PyTorch offrent un moyen simple d’exposer un modèle LLM via une interface web, mais cela ne nous permet toujours pas d’en utiliser plusieurs facilement et nous serions toujours limités aux modèles de type LLM, alors que nous voulions essayer la génération d’images et de vidéos.
J’ai fini par travailler sur ma propre solution : les modèles se chargeraient et se déchargeraient automatiquement en fonction des demandes de l’utilisateur, ils seraient tous facilement utilisables grâce à des interfaces Gradlio personnalisées, faciles à automatiser via une API et accompagnés d’une documentation facile à lire, grâce à FastAPI.
Après une semaine de travail, cela a fini par fonctionner plutôt bien. Il ne pouvait gérer qu’un seul modèle à la fois en raison de la mesure de la mémoire qui n’était pas si facile pour un modèle, mais cela fonctionnait très bien pour notre utilisation.
La partie la plus difficile a été que certains modèles fonctionnent avec une version différente de Python et de dépendances. Cela m’a obligé à ajouter un mécanisme de sous-processus avec la bibliothèque Pyro5 pour démarrer un environnement Conda indépendant avec la version correcte de Python et des dépendances. Cela a conduit à des bogues difficiles à trouver, mais cela a fini par très bien fonctionner.